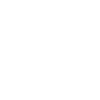Most ecommerce sellers think parcel tracking is just a simple string of location pings showing where their packages are right now. In reality, it’s a sophisticated data operation that ingests thousands of carrier events, normalizes inconsistent formats, and transforms messy signals into actionable intelligence. When done right, parcel tracking systems cut customer service inquiries by over half and power AI predictions that keep your delivery promises accurate. This guide breaks down how tracking systems unify multi-carrier data, overcome dirty data challenges, and enable you to optimize shipping efficiency while delighting customers with proactive communication.
Table of Contents
- Key takeaways
- How parcel tracking systems unify multi-carrier data
- Key methodologies for event normalization and status standardization
- Addressing data quality issues and leveraging AI for predictive ETAs
- Comparing carrier performance and maximizing post-purchase communication
- Optimize your freight booking and logistics with ORNER
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Unified carrier schema | Parcel tracking systems normalize carrier events into a single canonical schema for unified processing and cross carrier comparisons. |
| Data quality matters | Duplicates and non standard statuses distort timelines and degrade customer experience. |
| Automated alerts reduce inquiries | Proactive notifications based on universal statuses cut customer service inquiries. |
| AI driven ETA predictions | Consistent data enables analytics and AI based ETA models that improve delivery promises. |
How parcel tracking systems unify multi-carrier data
Every carrier speaks its own language. FedEx might call a delivery attempt “Left at Door,” while UPS labels it “Driver Release.” USPS uses different codes entirely. Without a common framework, you’re stuck toggling between carrier portals, manually reconciling statuses, and guessing what’s actually happening to your shipments. Parcel tracking systems rely on ingesting carrier-specific events via webhooks, APIs, or polling, then normalizing them into a canonical schema for unified processing.
Ingestion methods vary by carrier and your technical setup. Webhooks push real-time updates whenever a scan occurs, delivering instant visibility. API polling fetches status changes at scheduled intervals, trading immediacy for control. Some legacy carriers still require screen scraping or email parsing. Each method feeds raw events into your tracking system, where the real magic happens: normalization.
A canonical schema defines a standard structure for every tracking event. Think of it as a universal translator. Common fields include shipment_id, carrier, event_type, timestamp_utc, location, and status_code. By mapping every carrier’s quirky terminology into this shared format, you create a single source of truth. Now you can query all shipments with one SQL statement, build dashboards that compare FedEx and UPS side by side, and feed clean data into analytics engines without custom logic for each carrier.
The benefits compound fast. Clean, comparable event data lets you spot patterns: which carriers deliver fastest on specific lanes, where exceptions cluster, how weather delays ripple through your network. You can automate exception handling, trigger customer notifications based on universal statuses, and train AI models on consistent inputs. Choosing the best way to send a parcel for ecommerce logistics becomes data-driven instead of guesswork.
| Data element | Raw carrier format | Canonical schema |
|---|---|---|
| Status | “Out for Delivery,” “On Vehicle,” “In Transit to Destination” | OUT_FOR_DELIVERY |
| Timestamp | “12/15/2025 3:45 PM EST,” “2025-12-15T20:45:00Z” | 2025-12-15T20:45:00Z |
| Location | “Memphis TN 38125,” “Memphis, Tennessee” | {city: “Memphis”, state: “TN”, zip: “38125”} |
| Event type | “Delivered,” “Package Delivered,” “Successful Delivery” | DELIVERED |
Pro Tip: Monitor your data pipelines with automated alerts for ingestion errors. A webhook failure or API timeout can create blind spots that hurt customer experience and inflate support tickets.
Key methodologies for event normalization and status standardization
Raw carrier events arrive messy. You’ll see duplicate scans when a package gets scanned twice at the same facility, timestamps in local time zones that make sequencing impossible, and location strings like “SORTATION CENTER 5” that mean nothing to customers. Event normalization transforms this chaos into reliable, actionable data through four core processes.
First, event normalization maps carrier statuses to a shared ontology. Define a status taxonomy with clear, mutually exclusive categories: PICKUP, IN_TRANSIT, OUT_FOR_DELIVERY, DELIVERED, EXCEPTION, RETURNED. Every carrier status gets mapped to exactly one canonical value. FedEx “Picked Up” and UPS “Origin Scan” both become PICKUP. USPS “Notice Left” and FedEx “Delivery Exception” both map to EXCEPTION. This consistency lets you write business logic once and apply it everywhere.
Deduplication removes repeated identical events that clutter timelines and skew analytics. A package scanned three times in five minutes at a hub should register as one IN_TRANSIT event. Compare incoming events against recent history using a composite key of shipment_id, status_code, and timestamp within a tolerance window. Duplicates inflate event counts, confuse customers viewing tracking pages, and corrupt metrics like average transit time.
Timestamp normalization converts all local times to UTC. Carriers report scans in facility time zones, but your system needs a universal clock for sequencing events, calculating transit durations, and comparing cross-carrier performance. Parse timezone offsets, apply conversions, and store everything in UTC. Display local times to customers on the frontend, but keep your database and analytics in a single time standard.
Location standardization enriches and normalizes address data. Geocode facility names to coordinates, parse unstructured strings into structured address components, and validate against postal databases. This enables mapping visualizations, lane-based analytics, and accurate distance calculations for ETA models. Understanding logistics data quality challenges helps you anticipate where normalization will save you from downstream headaches.
- Ingest raw carrier event via webhook or API poll
- Parse event payload and extract core fields
- Map carrier status to canonical ontology value
- Convert timestamp to UTC and validate format
- Deduplicate against recent events for same shipment
- Normalize location data and enrich with geocoding
- Write normalized event to canonical schema table
- Trigger downstream processes like customer notifications or analytics updates
Pro Tip: Validate your mapping logic quarterly as carriers update their status codes and introduce new scan types. A missed mapping means events fall into an “unknown” bucket that breaks reporting and automation.
Addressing data quality issues and leveraging AI for predictive ETAs
Dirty data kills your delivery promises. When duplicate and non-standard data corrupt ETA calculations, you tell customers their package arrives Tuesday when it won’t show until Thursday. Trust evaporates, support tickets spike, and your brand takes the hit. Schema-first ingestion and continuous monitoring are essential for AI and machine learning in logistics.
![]()
Non-canonical statuses slip through when carriers introduce new codes or your mapping rules miss edge cases. These orphaned events don’t match your ontology, so they’re invisible to business logic. A package stuck at a facility might show as “in transit” because the exception scan used an unmapped code. Duplicates skew frequency analysis, making normal transit patterns look like delays. Both problems feed garbage into predictive models that depend on clean inputs.
Schema-first ingestion enforces data quality at the entry point. Define your canonical schema with strict validation rules: required fields, allowed values for enums, timestamp formats, location structure. Reject or quarantine events that don’t conform. This upfront discipline prevents dirty data from polluting your database and downstream systems. Monitor ingestion pipelines with dashboards tracking rejection rates, unmapped statuses, and duplicate percentages.
AI predictive models thrive on enriched, normalized data. Beyond basic tracking events, feed your models features like ingest_delay (time between actual scan and system receipt), weather data for origin and destination, historical carrier performance on the lane, package weight and dimensions, and shipment exception flags. Machine learning algorithms learn patterns invisible to rule-based systems: how Saturday pickups affect Monday delivery rates, which facilities consistently add delays, how weather impacts different carriers.
CRM-triggered interventions turn predictions into action. When your AI flags a high-probability delay or exception, automatically trigger workflows: reroute the shipment if possible, send proactive customer notifications with revised ETAs, escalate to support for high-value orders, or offer discounts to preserve satisfaction. These interventions reduce return rates and convert potential failures into loyalty-building moments.
“Dirty data (non-canonical statuses, duplicates) kills ETA accuracy; schema-first ingestion + monitoring essential for AI/ML in logistics.”
Maintaining data quality requires ongoing discipline:
- Implement automated validation at ingestion with clear rejection criteria
- Monitor mapping coverage weekly and update rules for new carrier codes
- Run deduplication audits to catch logic gaps that let twins through
- Enrich events with external data sources like weather APIs and facility databases
- Train AI models on clean historical data and retrain regularly as patterns shift
- Track prediction accuracy and investigate when actual delivery times diverge from forecasts
Exploring predictive analytics in logistics reveals how clean data transforms from operational necessity into competitive advantage.
Comparing carrier performance and maximizing post-purchase communication
Not all carriers perform equally. USPS low damage rates at 1.2% look attractive, but their 21-day claims resolution drags out reimbursements. UPS and FedEx resolve claims faster and deliver more consistent on-time performance, but their damage rates run higher on certain lanes. Prioritizing carriers by lane, weight, and package value balances on-time performance with damage risk.
USPS excels at lightweight, low-value shipments where their extensive last-mile network and affordable rates shine. Their damage rate of 1.2% beats competitors, but slow claims processing means you’re fronting replacement costs for weeks. For high-value or fragile items, that trade-off hurts. UPS offers the fastest claims resolution and strong on-time performance for commercial addresses, making them ideal for B2B shipments and time-sensitive deliveries. FedEx balances speed and reliability with competitive pricing on express services, though their damage rates vary by service level.
| Carrier | Damage rate | Avg claims duration | Claims resolution rate | Best use case |
|---|---|---|---|---|
| USPS | 1.2% | 21 days | 68% | Lightweight, low-value, residential |
| UPS | 2.1% | 12 days | 84% | B2B, time-sensitive, commercial |
| FedEx | 1.9% | 14 days | 79% | Express, balanced speed and cost |
Choosing the best shipping service for fragile items requires weighing damage risk against claims experience and delivery speed for your specific lanes.
Post-purchase communication remains shockingly underutilized. 75% of retailers rely on email-only for delivery updates, and 28% send no delivery email at all. Yet branded tracking pages and proactive multi-channel alerts cut “Where Is My Order” inquiries by 52%. Customers crave transparency. When you deliver it proactively, you reduce support costs and build trust.
Branded tracking pages replace generic carrier portals with your logo, colors, and messaging. Instead of sending customers to a sterile FedEx page, they land on your domain where you control the experience. Embed upsell opportunities, collect feedback, and reinforce your brand during a high-engagement moment. Proactive alerts via SMS, email, and push notifications keep customers informed without them needing to check manually: order confirmed, shipped, out for delivery, delivered, exception detected.
Effective post-purchase tactics include:
- Send shipment confirmation within minutes of carrier pickup with tracking link
- Trigger out-for-delivery alerts the morning of delivery so customers can plan
- Notify immediately when exceptions occur with revised ETA and resolution steps
- Deliver post-delivery messages asking for reviews or offering related products
- Provide self-service exception resolution like rescheduling delivery or redirecting to pickup locations
- Integrate carrier performance data to set realistic expectations and choose optimal carriers per shipment
Exploring parcel delivery service insights shows how communication strategy and carrier selection work together to elevate customer experience.
Pro Tip: Segment your communication strategy by order value and customer lifetime value. High-value orders and VIP customers get premium carriers, faster exception resolution, and white-glove communication. Budget-conscious segments get efficient, automated updates.
Optimize your freight booking and logistics with ORNER
You’ve learned how parcel tracking systems normalize multi-carrier data, overcome quality challenges, and power AI-driven efficiency. Now it’s time to put that knowledge to work. ORNER’s freight booking solutions integrate seamlessly with advanced parcel tracking, giving you end-to-end visibility from booking through final delivery. Whether you’re scaling cross-border operations or optimizing domestic lanes, our platform connects you with reliable carriers and real-time data.
Discover how freight booking explained simplifies your shipping workflows and reduces costs. Explore the best shipment tracking software to gain the visibility and control your operations demand. Partner with a reliable parcel delivery service that understands ecommerce logistics and delivers the performance your customers expect in 2026.
Frequently asked questions
What is the main purpose of normalizing carrier event data in parcel tracking?
Normalization creates a unified format that enables consistent processing and reliable status updates across multiple carriers. It eliminates confusion from differing carrier terminologies and data inconsistencies, allowing you to query all shipments with a single logic layer. This standardization powers analytics, automation, and AI models that depend on clean, comparable inputs.
How does poor data quality affect estimated delivery times (ETAs)?
Duplicates and non-canonical statuses introduce inaccuracies that degrade ETA precision, causing your predictions to miss actual delivery windows. When AI models train on dirty data, they learn false patterns and generate unreliable forecasts. Clean, monitored data ingestion with schema validation is critical for AI to generate delivery predictions customers can trust.
What benefits do proactive post-purchase communications provide?
Proactive alerts and branded tracking reduce customer support inquiries by over 50%, cutting operational costs while improving satisfaction. They enhance customer experience through transparency and timely updates, turning passive waiting into engaged anticipation. When customers know exactly where their order is and when it will arrive, trust in your brand deepens and repeat purchase rates climb.
Why is multi-carrier tracking better than relying on a single carrier?
Multi-carrier tracking reduces risk of capacity constraints and data silos that come with single-carrier dependency. It enables cross-carrier analytics, AI-powered ETAs, and exception automation that optimize your entire supply chain. You can route shipments dynamically based on real-time performance data, balancing cost, speed, and reliability. Learn more about multi-carrier tracking benefits and how they transform logistics operations.