TL;DR:
- Real-time data in logistics enables immediate decision-making by providing continuous operational information from sources like GPS and IoT sensors. Transitioning from batch updates to sub-minute streaming improves ETA accuracy, operational velocity, and margins by automating disruption responses. Implementing streaming SQL tools and starting with small use cases helps organizations quickly realize measurable efficiency gains.
Real-time data in logistics is the continuous, instantaneous flow of operational information that enables immediate decision-making across supply chains. Platforms like SONAR and Logility’s Orchestration Center have proven that sub-minute predictive ETA updates reduce ETA errors and improve supply chain margins by 2–5%. Technologies including GPS, RFID, IoT sensors, and streaming data platforms now form the backbone of any competitive logistics operation. If you are still running on 15–30 minute batch updates, you are not just behind. You are losing money on every shipment.
How real-time data improves logistics efficiency
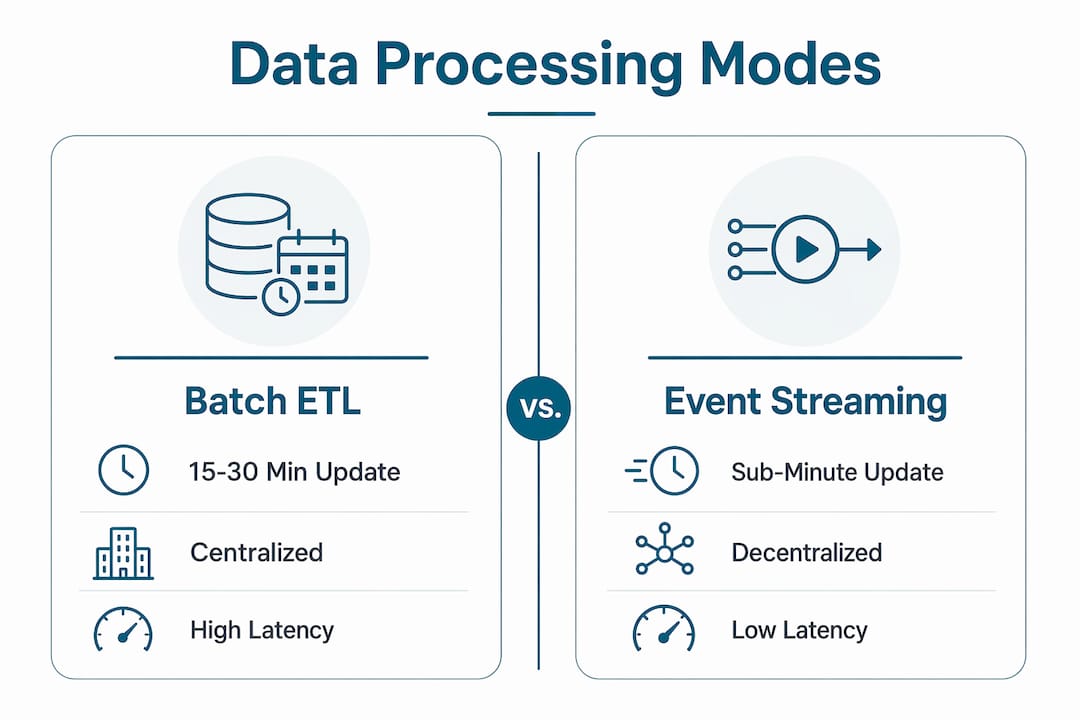
The shift from batch processing to live data feeds is the single biggest operational upgrade available to logistics teams right now. Traditional batch ETL systems update every 15–30 minutes. That gap is long enough for a delayed truck to miss a connection, a warehouse to oversell inventory, or a perishable shipment to sit in the wrong dock.

Streaming data closes that gap to seconds. The business impact is measurable and direct.
What changes when you go real-time:
- ETA accuracy: Sub-minute updates from platforms like SONAR replace guesswork with predictive positioning, reducing customer complaints and carrier penalties.
- Operational velocity: AI-powered command centers integrating rail, road, and sea data increase operational velocity by up to 4x by unifying carrier data into a single decision layer.
- Disruption response: Live alerts let dispatchers reroute trucks before delays compound. Without real-time alerts, teams react to problems after they have already cascaded.
- Fleet monitoring: A fleet of just 50 trucks generates 100,000 to 500,000 telematics events per hour. SQL-based stream processing is the only practical way to monitor that volume efficiently.
- Margin recovery: Automated disruption resolution through AI orchestration tools like Logility’s Orchestration Center increases margins by 2–5% by collapsing the time between detecting an exception and acting on it.
Pro Tip: Before investing in any streaming platform, map your current decision latency. Measure the average time from an operational event (a delay, a stockout, a route deviation) to the moment a human acts on it. That number is your baseline. Every technology decision should target reducing it.
The 4x velocity gain from unified AI command centers is not theoretical. It reflects what happens when dispatchers stop toggling between five separate systems and start working from one live operational picture. Logistics data analytics at this level turns reactive operations into proactive ones.
What technologies power real-time supply chain data?
The architecture behind live logistics data is more accessible than most teams assume. Streaming SQL tools are democratizing real-time monitoring by letting logistics analysts use familiar SQL skills instead of learning complex custom code.
Core data sources
Every real-time logistics system starts with telemetry. GPS units report vehicle position every few seconds. RFID tags log inventory movements at dock doors and warehouse shelves. CAN bus systems inside trucks capture engine diagnostics, fuel consumption, and driver behavior. IoT sensors on cold-chain containers report temperature and humidity continuously. These sources generate millions of events per day across a mid-size fleet.
Streaming platforms and processing frameworks
The data from those sources needs a processing layer. Apache Kafka handles high-throughput event ingestion. Apache Flink and ksqlDB process those streams in real time, applying filters, aggregations, and alerts without waiting for a batch window. Spark Structured Streaming offers another option for teams already invested in the Spark ecosystem. Managed serverless Flink and ksqlDB enable sub-5-second reaction times for pricing and routing decisions. That speed is what separates event-driven ETL from traditional pipelines.
Legacy batch ETL vs. event-driven stream processing
| Dimension | Legacy Batch ETL | Event-Driven Streaming |
|---|---|---|
| Update frequency | Every 15–30 minutes | Sub-second to sub-minute |
| Decision latency | High. Problems surface after the fact. | Low. Alerts trigger before cascades. |
| Data integration | Pre-joined in a central warehouse | Query-time cross-source joins |
| Infrastructure complexity | Familiar but rigid | Requires streaming platform expertise |
| Best fit | Historical reporting | Live operations and exception management |
The most important architectural insight here is about centralization. Experienced teams avoid dumping all data into one massive warehouse before analysis. Instead, they connect directly to TMS, WMS, and IoT APIs at query time. This approach cuts latency and avoids the months-long data migration projects that stall most analytics initiatives.
Pro Tip: If your team already knows SQL, start with RisingWave or ksqlDB before evaluating custom Flink deployments. The learning curve is far shorter, and you can have a working real-time dashboard in days rather than months.
What are the biggest pitfalls in implementing live tracking logistics?
Most real-time data projects fail before they deliver value. The failure mode is almost always the same: teams underestimate integration complexity and overestimate their capacity to build custom solutions.
Here are the most common mistakes and how to avoid them:
- Building custom stream processing from scratch. Most teams that write bespoke Flink jobs from zero spend six months on infrastructure instead of analytics. Managed services like serverless Flink reduce maintenance overhead and improve reliability without requiring a dedicated platform engineering team.
- Over-centralizing data before analysis. Pulling every data source into one warehouse before running queries adds weeks of pipeline work and introduces new failure points. Query-time integration connecting directly to TMS, WMS, and IoT APIs is faster and more flexible.
- Ignoring data quality at the source. A GPS unit that drops signal for 30 seconds creates a phantom delay in your ETA model. Governance rules must catch and flag bad data at ingestion, not after it has already triggered a false alert.
- Alert fatigue from poor tuning. Real-time systems can generate thousands of alerts per hour. Without threshold tuning and alert prioritization, dispatchers start ignoring notifications entirely. Start with five critical alert types and expand only after those are proven useful.
- Skipping the phased approach. Trying to automate everything at once is the fastest way to a failed implementation. Start with one use case, such as live ETA updates for a single lane. Prove the value in dollars, then expand.
The phased approach also applies to data integration in logistics. Connect your highest-volume data source first. Measure the operational improvement. Use that result to justify the next integration. This builds organizational confidence alongside technical capability.
Real-world applications of real-time data in logistics
The clearest way to understand the value of live operational data is through specific use cases with measurable outcomes.
Fleet health and compliance monitoring is the most immediate application for trucking operations. A fleet of 50 trucks generating up to 500,000 telematics events per hour requires automated processing to flag engine faults, Hours of Service violations, and fuel anomalies before they become breakdowns or fines. Manual review of that volume is impossible. Streaming SQL makes it routine.
Perishable goods delivery is where ETA accuracy directly affects product quality and customer satisfaction. Near-real-time rerouting based on live traffic and temperature sensor data keeps cold-chain shipments on schedule. A 10-minute delay in detecting a refrigeration fault can mean a full load of product lost.
Automated disruption resolution through tools like Logility’s Orchestration Center represents the next level. These systems sit above existing TMS and WMS platforms and automate approved responses to detected exceptions. When a port delay is detected, the system can automatically notify downstream carriers, adjust inventory allocations, and update customer ETAs without waiting for a human to process each step. The margin improvement of 2–5% from this automation compounds across thousands of shipments per year.
| Use Case | Technology Used | Business Outcome |
|---|---|---|
| Fleet telematics monitoring | Streaming SQL, Apache Kafka | Reduced breakdowns and compliance violations |
| Perishable ETA refinement | GPS streaming, IoT sensors | Lower spoilage rates, higher on-time delivery |
| Disruption auto-resolution | AI orchestration (Logility) | 2–5% margin improvement |
| Inventory synchronization | RFID, WMS API integration | Fewer stockouts and overstock events |
| Freight audit and anomaly detection | Real-time billing data streams | Revenue recovery from billing errors |
Real-time inventory synchronization is critical for ecommerce operations running across multiple fulfillment centers. When a warehouse management system updates inventory in real time, the ecommerce storefront reflects accurate stock levels immediately. This eliminates overselling and the customer service costs that follow. Or-ner’s warehouse automation capabilities are built around exactly this kind of live inventory visibility.
Freight audit automation is an underrated revenue recovery tool. Billing errors and accessorial charge discrepancies are common in high-volume freight. Real-time anomaly detection flags mismatches between contracted rates and invoiced amounts at the moment of billing, not weeks later during a manual audit cycle.
Key takeaways
Real-time data in logistics delivers measurable margin gains only when streaming architecture, query-time data integration, and automated orchestration work together as a system.
| Point | Details |
|---|---|
| Batch updates cost money | Moving from 15–30 minute batch to sub-minute streaming improves supply chain margins by 2–5%. |
| Orchestration beats visibility | Automating approved responses to exceptions collapses insight-to-action time and drives margin recovery. |
| SQL skills transfer directly | Streaming SQL platforms like RisingWave and ksqlDB let existing analysts build real-time dashboards without new language skills. |
| Phased implementation wins | Start with one high-value use case, prove the ROI, then expand to avoid failed big-bang deployments. |
| Query-time integration is faster | Connecting to TMS, WMS, and IoT APIs at query time beats centralizing all data into one warehouse before analysis. |
The part most teams get wrong about real-time data
I have watched logistics teams invest heavily in visibility tools and then wonder why their margins did not move. The problem is almost never the data. It is the gap between seeing something and doing something about it.
Decision latency is the silent killer in logistics profitability. You can have a beautiful real-time dashboard showing a delayed shipment and still lose money if the response takes 45 minutes because three people need to approve a reroute. The insight is instant. The execution is not.
The teams that actually move the margin needle are the ones investing in orchestration, not just monitoring. Logility’s Orchestration Center model, where AI agents execute pre-approved responses automatically, is the right direction. It is not about removing humans from the loop. It is about removing humans from the parts of the loop that do not require judgment.
The other thing I would push back on is the assumption that real-time data systems are only for large enterprises. The streaming SQL tools available in 2026 are genuinely accessible to mid-size operations. A regional carrier with 50 trucks can build a working telematics monitoring system in weeks using managed services. The barrier is not technology anymore. It is organizational willingness to start small and iterate.
My honest advice: pick one lane, one data source, and one decision you want to automate. Build that. Measure it. Then let the results make the case for the next step. The teams that try to boil the ocean with a full real-time supply chain overhaul on day one are the ones I see abandoning the project by month six.
— Maayan
How Or-ner puts real-time data to work for your business
Or-ner is built for logistics and supply chain professionals who need more than a tracking number. The platform combines reliable courier services with live shipment visibility, automated exception alerts, and data-integrated fulfillment across ocean, air, and land transport modes.
Whether you are managing cross-border ecommerce shipments or scaling a wholesale operation, Or-ner’s cloud logistics platform connects your orders, inventory, and carrier data into one operational view. You get the kind of real-time intelligence that used to require a dedicated data engineering team, built directly into your fulfillment workflow. Talk to Or-ner about putting live logistics data to work for your operation today.
FAQ
What is real-time data in logistics?
Real-time data in logistics is the continuous flow of operational information from sources like GPS, RFID, and IoT sensors that enables immediate decision-making across supply chains. It replaces delayed batch updates with live visibility into shipment status, inventory levels, and fleet performance.
How does live tracking improve supply chain margins?
Transitioning from batch updates to sub-minute streaming data reduces ETA errors and improves supply chain margins by 2–5%, according to SONAR platform data. Automated disruption resolution through orchestration tools compounds those gains across high shipment volumes.
What streaming technologies do logistics teams use most?
Apache Kafka, Apache Flink, ksqlDB, and RisingWave are the most widely adopted platforms for real-time logistics data processing. Managed serverless versions of these tools enable sub-5-second reaction times without requiring a dedicated platform engineering team.
How do i start implementing real-time data in my logistics operation?
Start with one high-value use case, such as live ETA updates for a single lane or telematics monitoring for your fleet. Prove the ROI in measurable terms before expanding to additional data sources or automated workflows.
Is real-time logistics data only practical for large enterprises?
No. Streaming SQL platforms like RisingWave and ksqlDB are accessible to mid-size operations and regional carriers. A fleet of 50 trucks can have a working real-time monitoring system running in weeks using managed services and existing SQL skills.